In recent years, machine learning (ML) has become integral to numerous industries, from healthcare and finance to retail and transportation. The rise of ML has been fueled by the availability of large datasets and the computational power to process them. However, as more data is generated and collected, concerns around data privacy and security have also grown. This has led to the development of federated learning, a decentralized approach to machine learning that offers a promising solution to these challenges.

The Traditional Approach: Centralized Data Collection
Before delving into federated learning, it’s essential to understand the traditional approach to machine learning. In most cases, data from various sources is collected, centralized, and then used to train machine learning models. This centralized approach has been practical in producing high-quality models, but it has significant drawbacks, particularly regarding data privacy and security.
When data is centralized, it becomes vulnerable to breaches, leaks, and misuse. This is especially problematic in sensitive domains like healthcare, where patient data must be protected, or finance, where customer data is a prime target for cybercriminals. Additionally, centralizing data can be logistically challenging and expensive, mainly when dealing with large and geographically dispersed datasets.
The Rise of Federated Learning
Federated learning was introduced as a solution to the problems associated with centralized data collection. Google first popularized the concept in 2017 to improve models’ accuracy on mobile devices without compromising user privacy. The core idea behind federated learning is simple: instead of bringing the data to the model, get the model to the data.
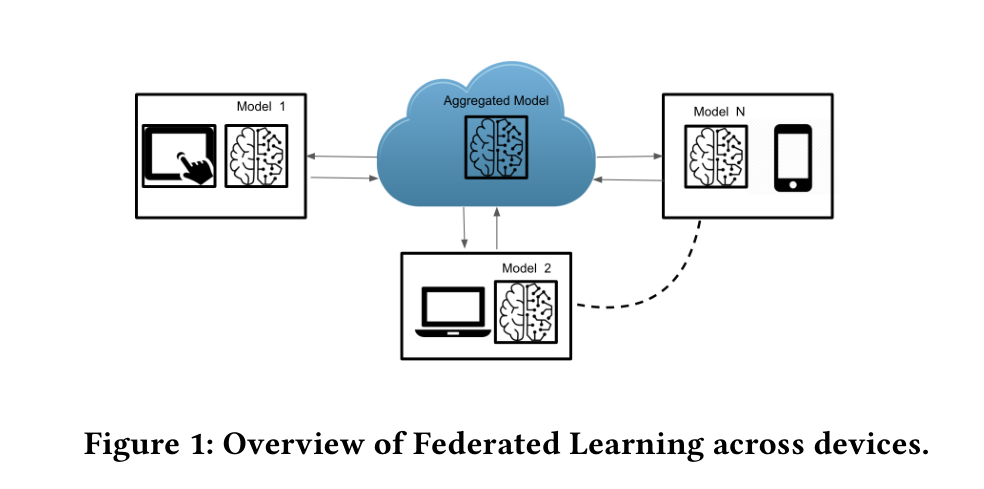
In federated learning, the model is distributed to multiple devices or servers, each holding a portion of the data. These devices train the model locally using their own data, and then only the updated model parameters (not the raw data) are sent back to a central server. The central server aggregates these updates to produce a global model that benefits from the data held on all the devices without ever accessing the data.
How Federated Learning Works
Federated learning operates in several key steps:
- Model Initialization: The process begins with a base model initialized on a central server. This model can be a simple neural network, a decision tree, or a machine learning algorithm.
- Distribution of the Model: The base model is then distributed to multiple devices or servers, often called “clients.” These clients could be mobile phones, IoT devices, or other systems that generate and hold data locally.
- Local Training: Each client trains the model using its local data. The training process is similar to traditional machine learning, where the model is updated based on the data it is exposed to.
- Model Update: After training, each client sends only the model updates (e.g., gradients or weight adjustments) back to the central server. Notably, the raw data never leaves the client’s device.
- Aggregation: The central server aggregates the updates from all the clients to create a new, improved global model. This aggregation can be as simple as averaging the updates or involve more complex techniques to handle client discrepancies.
- Iteration: The updated global model is then redistributed to the clients, and the process repeats. This iterative process continues until the model reaches a desired level of accuracy or a predetermined number of iterations is completed.
Here are some real-world examples of how federated learning is being applied across different industries:
1. Google’s Gboard Keyboard
Google uses federated learning to improve the predictive text and autocorrect functionality of its Gboard keyboard on Android devices. The model learns from users typing data on the device without sending the raw data to Google’s servers. Instead, updates to the model are aggregated from many devices, improving the keyboard’s performance for everyone while keeping individual user data private.
2. Apple’s Siri and Dictation
Apple employs federated learning to enhance the accuracy and personalization of Siri and dictation services across its devices. Apple can improve these services by processing data locally on each user’s device without compromising user privacy. Updates from individual devices contribute to a global model, which continuously evolves to understand better and predict user intentions.
Mammen, P. M. (2021). Federated learning: Opportunities and challenges. arXiv preprint arXiv:2101.05428.
Advantages of Federated Learning
Federated learning offers several advantages over traditional centralized approaches:
- Data Privacy: Since raw data never leaves the client’s device, federated learning significantly reduces the risk of data breaches and misuse. This is particularly important in sectors like healthcare and finance, where data privacy is paramount.
- Reduced Data Transfer: By keeping data local, federated learning reduces the need for large-scale data transfers, which can be costly and time-consuming. This is especially beneficial when bandwidth is limited or data is distributed across multiple locations.
- Scalability: Federated learning is inherently scalable because it allows for parallel processing across multiple devices. As more clients join the network, the model can improve without requiring additional centralized resources.
- Personalization: Because the model is trained on local data, it can be more personalized to individual users or devices’ specific needs and characteristics. This is particularly useful in applications like personalized recommendations or adaptive learning systems.
Challenges and Limitations
Despite its many advantages, federated learning is not without its challenges:
- Heterogeneity of Data: In federated learning, the data held by different clients can vary significantly in quantity, quality, and distribution. This can lead to model convergence and performance issues, as the aggregated updates may not reflect a uniform learning process.
- Communication Overhead: While federated learning reduces the need for data transfer, frequent communication between clients and the central server is required to share model updates. This can be a bottleneck, particularly in environments with limited connectivity.
- Security Risks: Although federated learning enhances data privacy, it is not immune to security risks. For example, adversarial clients could send malicious updates to corrupt the global model. Additionally, sophisticated attacks could reverse-engineer the model updates to infer information about the local data.
- Computational Resource Constraints: Federated learning often relies on devices with limited computational resources, such as smartphones or IoT devices. This can constrain the complexity of the models that can be trained locally and the speed at which training can occur.
The Future of Federated Learning
Federated learning is still a relatively new field but rapidly evolving. Researchers are exploring ways to address its challenges, such as developing more efficient aggregation techniques, improving communication protocols, and enhancing security measures. As these advancements continue, federated learning will likely play an increasingly important role in developing privacy-preserving AI systems.
Moreover, federated learning aligns well with broader trends in technology, such as the shift toward edge computing and the growing emphasis on data privacy. As more devices become connected and more data is generated at the edge, federated learning offers a scalable and secure way to harness this data for machine learning.
In conclusion, federated learning represents a paradigm shift in how we approach machine learning, decentralizing the training process and keeping data local offers a powerful solution to data privacy, security, and scalability challenges. As this technology matures, it has the potential to unlock new possibilities for AI while ensuring that privacy and data sovereignty remain at the forefront.